
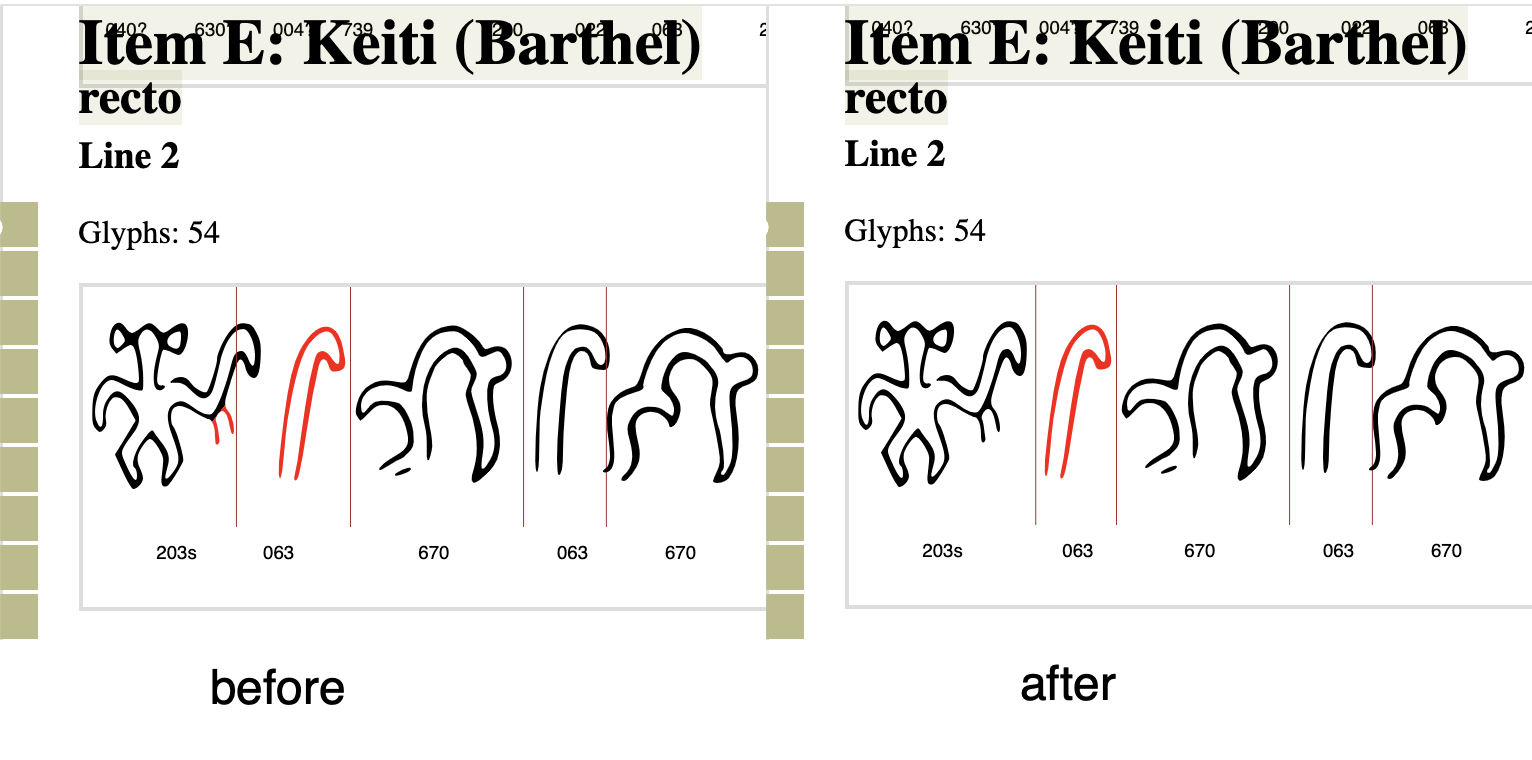
Creating the XML corpus required quite a bit of manual labor. Especially fiddly was subdividing the image files into individual glyphs. Obviously occasional errors happen. Cutting the svg images into their subparts, and then putting the correct ones back together again, and then making sure that each one has the correct number of images to match the number of glyphs and in the correct order.
So even though I did all of this over 10 years ago, and have checked through it in different ways many times, sometimes I still discover errors. Such as the example above on Keiti, recto, line 2. The first two glyphs were mis-parsed. That’s fixed now.